TSC - Compilador de Scheme para RISC-V (parte 1)
Tradutores são um conceito que sempre me chamou muito a atenção. É incrível como linhas de código e um pouco de teoria de autômatos pode converter instruções em uma linguagem fonte para outra linguagem. Mesmo com esse meu fascínio, tradutores são um tanto complexos de se entender, e eu nunca havia realmente tentado projetar um. Ao cursar a matéria na faculdade, finalmente pude dar o pontapé inicial a um projeto que estava em minha cabeça há muito tempo: um compilador de Scheme para Assembly RISC-V.
Scheme e os Lisps⌗
Scheme é uma linguagem de programação bem antiga, que data dos primeiros sistemas computacionais. É um dos muitos dialetos da família de linguagens Lisp, que delimita expressões da linguagem entre parênteses. Diferentemente de linguagens como C e Fortran, que datam da mesma época, onde impera o paradigma de programação imperativo (você diz ao programa como fazer algo), Scheme é um proponente do paradigma de programação funcional (você diz ao programa o que fazer). Entretanto, por mais que Scheme facilite a implementação do paradigma funcional (recursividade, aplicação de funções), é possível programar de forma imperativa nessa linguagem.
Me interessei por Lisps há muito tempo, mas nunca cheguei a programar nada em Lisp até o início de 2021, quando instalei o melhor software já inventado: o GNU Emacs. O Emacs é um editor de texto escrito inicialmente em meados de 1970, e que sobreviveu ao teste do tempo para ser relevante até hoje por conta de uma característica que o diferencia: a capacidade de estender o editor por meio de uma linguagem de programação Lisp. O Emacs pode ser aprimorado na mesma linguagem em que é escrito, o Emacs Lisp (o que eu acho muito legal), o que permite que o editor se torne uma extensão natural do trabalho do programador, que pode modificá-lo para fazer o que ele quiser.
Essa grande tangente foi só para expressar meu amor pelo Emacs e como ele se tornou parte integral da minha vida como programador. Voltando a falar do meu projeto, temos que falar de outra parte essencial desse projeto: a especificação RISC-V.
RISC-V⌗
RISC-V é uma arquitetura de conjunto de instruções (do inglês Instruction Set Architecture ou ISA) que é disponibilizada de forma aberta. Essa ISA disponibiliza um conjunto de instruções que podem ser traduzidas para código de máquina para uma máquina final.
O mais interessante do RISC-V é que qualquer pessoa pode pegar essa ISA e implementar o próprio processador em um FPGA, por exemplo. Isso é muito interessante porque permite que pessoas experimentem com novas ideias para processadores utilizando recursos abertos, diferente das arquiteturas fechadas de gigantes como Intel e AMD, que possuem processadores x86, e ARM, com a arquitetura ARM.
Um problema que eu tive na faculdade de ciência da computação é que o único momento que eu interagi com a arquitetura RISC-V foi nas aulas de arquitetura de computadores. Nas aulas eu tinha que escrever código intermediário de montagem para RISC-V diretamente em um editor de texto. O problema dessa abordagem é que na vida real o código é escrito em uma linguagem de alto nível, e então convertida para um formato intermediário (a exemplo desse código intermediário) ou para instruções binárias. Portanto, tive a ideia de escrever um compilador que converte código fonte escrito em uma linguagem de alto nível (nesse caso, Scheme) e gera código intermediário RISC-V a partir desse arquivo fonte.
Texugo Scheme Compiler (TSC)⌗
O TSC, o compilador gerado nesse projeto, é apenas uma prova de conceito para a construção de um tradutor de Scheme para RISC-V. O processo de compilação se dá pelas seguintes etapas:
- Análise léxica
- Análise sintática;
- Análise semântica;
- Geração de código.
Análise do código é a parte mais importante do processo (não é à toa que existem 3 etapas de análise), e permitem verificar que o programa fonte foi escrito corretamente, na ordem correta e seguindo as diretrizes da linguagem.
O compilador em questão realiza uma única passagem: as 3 análises e a geração de código ocorrem ao mesmo tempo. Também existem compiladores que realizam diversas passagens, e que são muito mais eficientes. Eu, entretanto, não estou ligando para eficiência, eu só preciso que a compilação seja bem rápida (afinal, esse projeto é para aprendizado). Para realizar essas análises eu utilizo duas ferramentas de código aberto: GNU Flex e GNU Bison. Em resumo, o GNU Flex permite a geração de analisadores léxicos e o GNU Bison permite a geração de analisadores sintáticos. Dessa forma, eu posso me preocupar apenas com a lógica da linguagem e não com os processos de verificação. Além das análises, também será mantida uma tabela de símbolos, responsável por armazenar dados de variáveis utilizadas no programa. Dessa forma, é possível verificar onde as variáveis estão na memória e gerar o código correspondente, além de fazer o lançamento de erros corretamente. O diagrama abaixo mostra uma visão macro do que o compilador deve ser.
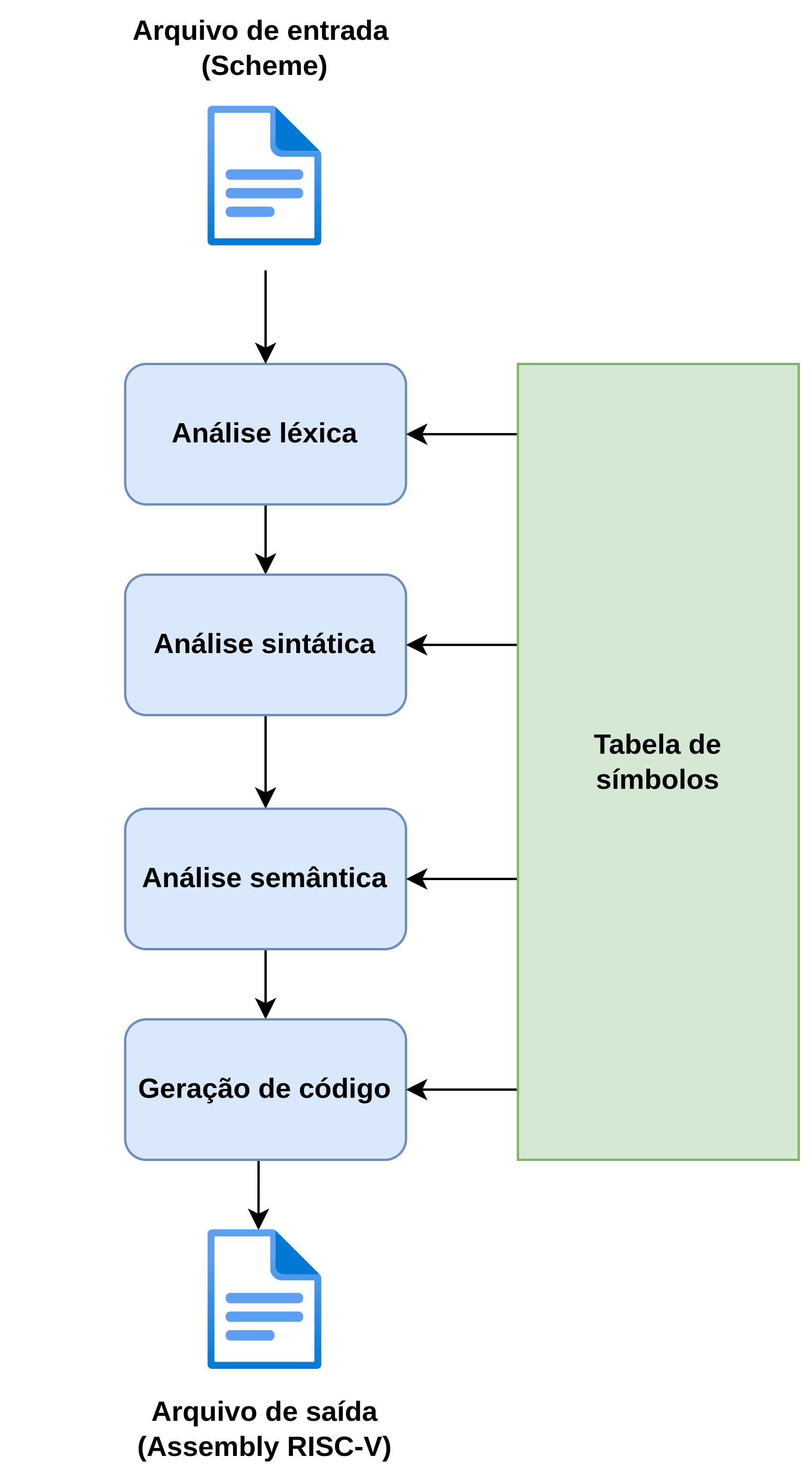
De início, o compilador deve fazer algumas coisas:
- Atribuição de variáveis;
- Operações aritméticas com inteiros;
- Impressão para saída padrão.
Realizando essas três funcionalidades, é possível escrever programas bem simplificados, mas já é um começo.
Considerações finais⌗
Essa postagem foi apenas para introduzir esse meu novo projeto em andamento. Em um futuro próximo começarei a postar o progresso do desenvolvimento do compilador por aqui. Até lá, happy hacking ;)