Assistente de código dentro de casa
Os assistentes de código tomaram o mundo de surpresa nos últimos anos, com a aparição do Github Copilot. Hoje eu vou ensinar como rodar um desses em uma máquina na sua casa sem pagar uma assinatura caríssima.
Github Copilot e outros assistentes em nuvem⌗
Para aqueles que não estão familiarizados, o Github Copilot é um assistente de código disponível a quem tem uma conta do Github. O que começou com uma novidade engraçadinha hoje é um projeto enorme com preços cada vez mais inacessíveis[1]:

Mas tudo bem, outras plataformas têm preços mais acessíveis para esse tipo de funcionalidade, certo? Errado!
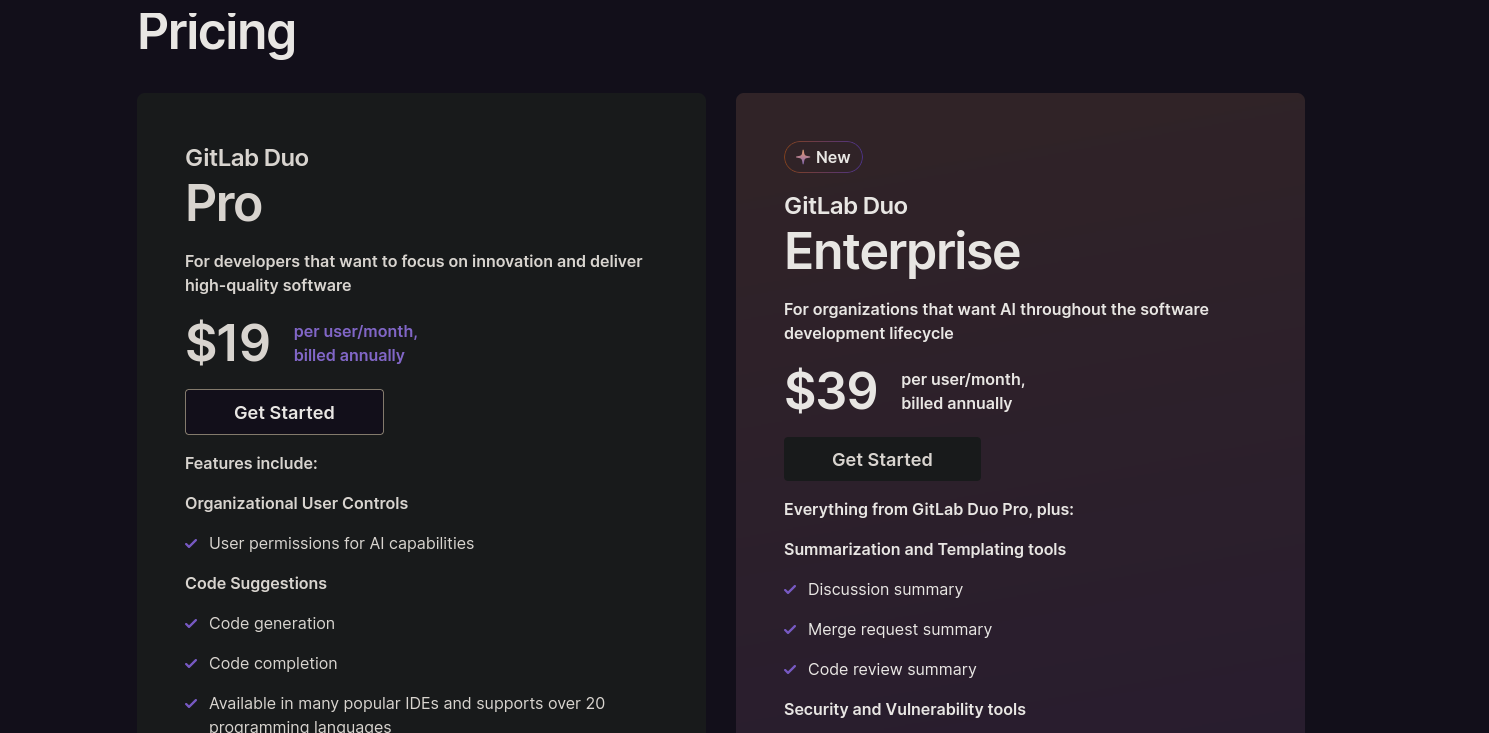
Infelizmente, as duas grandes plataformas de repositório de código em Git oferecem soluções pagas para assistentes de código.
Para quem mora do lado de lá do Equador, US$ 19 podem não parecer tanta coisa, mas num país onde a cotação já passou de 5.80, pagar essa pequena fortuna por mês pra um robô te ajudar a programar é um pouco sem noção inacessível.
Empresas também estão começando a entender o poder e a produtividade que esse tipo de ferramenta traz, mas ferramentas de IA nem passam pela cabeça da maioria da alta gerência (principalmente pro povo da TI, que ninguém lembra num geral), então pode esquecer o Copilot como parte do orçamento anual.
Por conta disso, comecei a montar um projeto de um assistente de código 0800 que roda diretamente na sua máquina pessoal (ou em um servidor de sua posse).
CodeGemma-2b + llama.cpp⌗
Em 2024, no entanto, a Google, um dos poucos expoentes na área de modelos de linguagem de código aberto, nos agraciou com o CodeGemma, um modelo de linguagem de tamanho razoável, voltado para geração de código localmente. O modelo tem duas versões, com 2 bilhões e 7 bilhões de parâmetros. O CodeGemma-2b tem 2 bilhões de parâmetros, uma quantidade que, ainda que pequena comparada com outros modelos, oferece respostas muito mais rápidas que modelos de 7 ou 13 bilhões de parâmetros, como o CodeGemma-7b e o LLaMa2- 13b. Essa característica é crucial para quem está desenvolvendo código e precisa de uma resposta rápida para um determinado prompt.
Esse modelo está disponível em formato GGUF, o que é essencial para uso em ferramentas, como a outra estrela dessa postagem: o llama.cpp. Já citei essa ferramenta na postagem sobre o assistente de voz que criei uns meses atrás. O uso de um modelo GGUF permite executá-lo nessa ferramenta como um servidor web, e enviar prompts como requisições HTTP.
Para executar uma instância local do llama.cpp é necessário ter o Docker instalado. Além disso, a ferramenta tem várias versões, compiladas para tirar vantagem do seu hardware. Se você tem uma placa de vídeo da Nvidia com suporte para modelos de IA (com os chamados núcelos CUDA), é recomendável utilizar uma imagem já compilada com as dependências do CUDA.
Além disso, é necessário baixar o modelo do CodeGemma. Ele está disponível no HuggingFace para download[3] (talvez com algum termo de licença para assinar).
Por fim, basta juntar tudo em um arquivo docker-compose.yml
services:
copilot:
image: ghcr.io/ggerganov/llama.cpp:server-cuda
ports:
- "5000:5000"
volumes:
- ./codegemma-2b-GGUF:/models
command: "-m models/codegemma-2b-f16.gguf --port 5000 --host 0.0.0.0 -ngl 40 -c 256"
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1 # alternatively, use `count: all` for all GPUs
capabilities: [gpu]
O volume ./codegemma-2b-GGUF é a pasta onde baixei e extraí o modelo. As portas podem ser modificadas, desde que você modifique o comando de execução na diretiva command.
Por fim basta executar o comando:
docker compose up -d copilot
Usando o copiloto no editor de código⌗
"Matheus, mas quando é que eu vou poder usar isso dentro do meu editor de texto?"
Esse aqui ☝️ é literalmente você neste momento.
Sem pressa, vamos tratar dessa parte agora.
Eu desenvolvi um programa em Emacs Lisp para o envio de um prompt a partir da área selecionada no meu editor de texto, o Emacs, e que insere a resposta do servidor do llama.cpp novamente em sequência à área selecionada do código. O programa também remove as estruturas de controle criadas pelo modelo do CodeGemma.
O resultado é um assistente de código que me retorna resultados rápidos para prompts em tempo real.
Para utilizar o programa acima, clone o repositório[4] em algum local no seu computador (recomendo em uma pasta .emacs.d/etc/). Em seguida, carregue o arquivo com o comando load-file
M-x load-file .emacs.d/etc/emacs-copilot/codegemma.el
Para gerar código, selecione uma área do texto no editor e execute M-x mlemosf/copilot. Recomendo atrelar esse comando a algum atalho de teclado, como shift tab.
Exemplos⌗
Abaixo estão alguns exemplos da execução da aplicação
- JavaScript / NodeJS
Prompt:
// Function for retrieving a user object from firebase
app.get('/user/{id}', (req, res) => {
Resultado gerado
// Function for retrieving a user object from firebase
app.get('/user/{id}', (req, res) => {
const uid = req.params.id;
const userRef = db.collection('users').doc(uid);
userRef.get()
.then(doc => {
if (doc.exists) {
res.json(doc.data());
} else {
res.status(404).send('User not found');
}
})
.catch(error => {
res.status(500).send('Error retrieving user');
});
});
- Python / Django
Prompt
# Django model for a user class with 'id', 'name' and 'age' parameters with __init__ method
class User(models.Model):
Resultado gerado:
# Django model for a user class with 'id', 'name' and 'age' parameters with __init__ method
class User(models.Model):
id = models.IntegerField(primary_key=True)
name = models.CharField(max_length=255)
age = models.IntegerField(null=True)
def __init__(self, id, name, age):
self.id = id
self.name = name
self.age = age
Vale ressaltar que em ambos os exemplos o código foi gerado a partir de onde o prompt acaba, e eu coloquei todo o código acima para fins de legibilidade.
Pensamentos finais⌗
Eu não cheguei até aqui para dizer que essa ferramenta substitui (ou parece) os esforços multimilionários de empresas como a Microsoft. Essa ferramenta é muito mais simples e roda em hardware comum, estando propensa a falhas do hardware, em contraste com essas ferramentas em nuvem. Ela também tem limitações de quanto código pode gerar em sequência, algo que pode ser modificado nas configurações do llama.cpp para se adequar à sua máquina. Minha placa de vídeo tem 4 GB de memória de vídeo, e uma janela de 512 tokens é um limite que eu encontrei em meus testes.
Além disso, notei que a ferramenta é muito boa em gerar código boilerplate para tarefas mais comuns, mas que não se adequa tão bem a códigos muito específicos do negócio.
No entanto, essa ferramenta me oferece algo que é muito mais importante do que desempenho e comodidade: a privacidade de desenvolver código com um assistente diretamente em minha máquina, com a certeza de que ele não será usado para treinar outros modelos de linguagem sem minha permissão expressa, e sabendo que ele se adequa às minhas necessidades específicas. Essa paz de espírito vale todo o tempo investido nesse projeto.
Caso tenha alguma dúvida sobre o funcionamento do projeto ou de alguma das outras bibliotecas que eu escrevi, sinta-se a vontade para abrir uma issue no Github ou me mandar um email. No mais,
Happy hacking ;).
Referências⌗
[1]: Github Copilot - Acessado 15/11/2024
[2]: Gitlab Duo - Acessado 15/11/2024
[3]: google/codegemma-2b-GGUF
[4]: mlemosf/emacs-copilot